GeneralNewsExtractor-新闻网页正文通用抽取器-GeneralNewsExtractor下载 v0.2.6官方版
时间:2025/1/13作者:未知来源:盘绰网教程人气:
- [摘要]GeneralNewsExtractor(新闻网页正文通用抽取器)是一个基于《基于文本及符号密度的网页正文提取方法》论文用Python实现的正文抽取器,可以用来提取 HTML 中正文的内容、作者、标...
GeneralNewsExtractor(新闻网页正文通用抽取器)是一个基于《基于文本及符号密度的网页正文提取方法》论文用Python实现的正文抽取器,可以用来提取 HTML 中正文的内容、作者、标题。
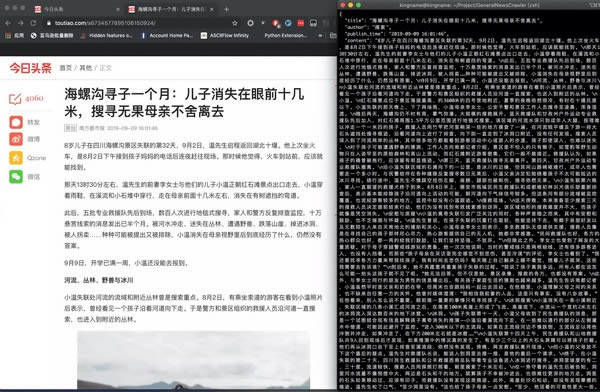
开发介绍
项目起源
开发这个项目,源自于我在知网发现了一篇关于自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
这篇论文中描述的算法看起来简洁清晰,并且符合逻辑。但由于论文中只讲了算法原理,并没有具体的语言实现,所以我使用 Python 根据论文实现了这个抽取器。并分别使用今日头条、网易新闻、游民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻做了测试,发现提取效果非常出色,几乎能够达到100%的准确率。
项目现状
在论文中描述的正文提取基础上,我增加了标题、发布时间和文章作者的自动化探测与提取功能。
目前这个项目是一个非常非常早期的 Demo,发布出来是希望能够尽快得到大家的使用反馈,从而能够更好地有针对性地进行开发。
本项目取名为抽取器,而不是爬虫,是为了规避不必要的风险,因此,本项目的输入是 HTML,输出是一个字典。请自行使用恰当的方法获取目标网站的 HTML。
本项目现在不会,将来也不会提供主动请求网站 HTML 的功能。
常见的网络操作系统有UNIX、Netware、Windows NT、Linux等,网络软件的漏洞及缺陷被利用,使网络遭到入侵和破坏。下载地址
- PC版